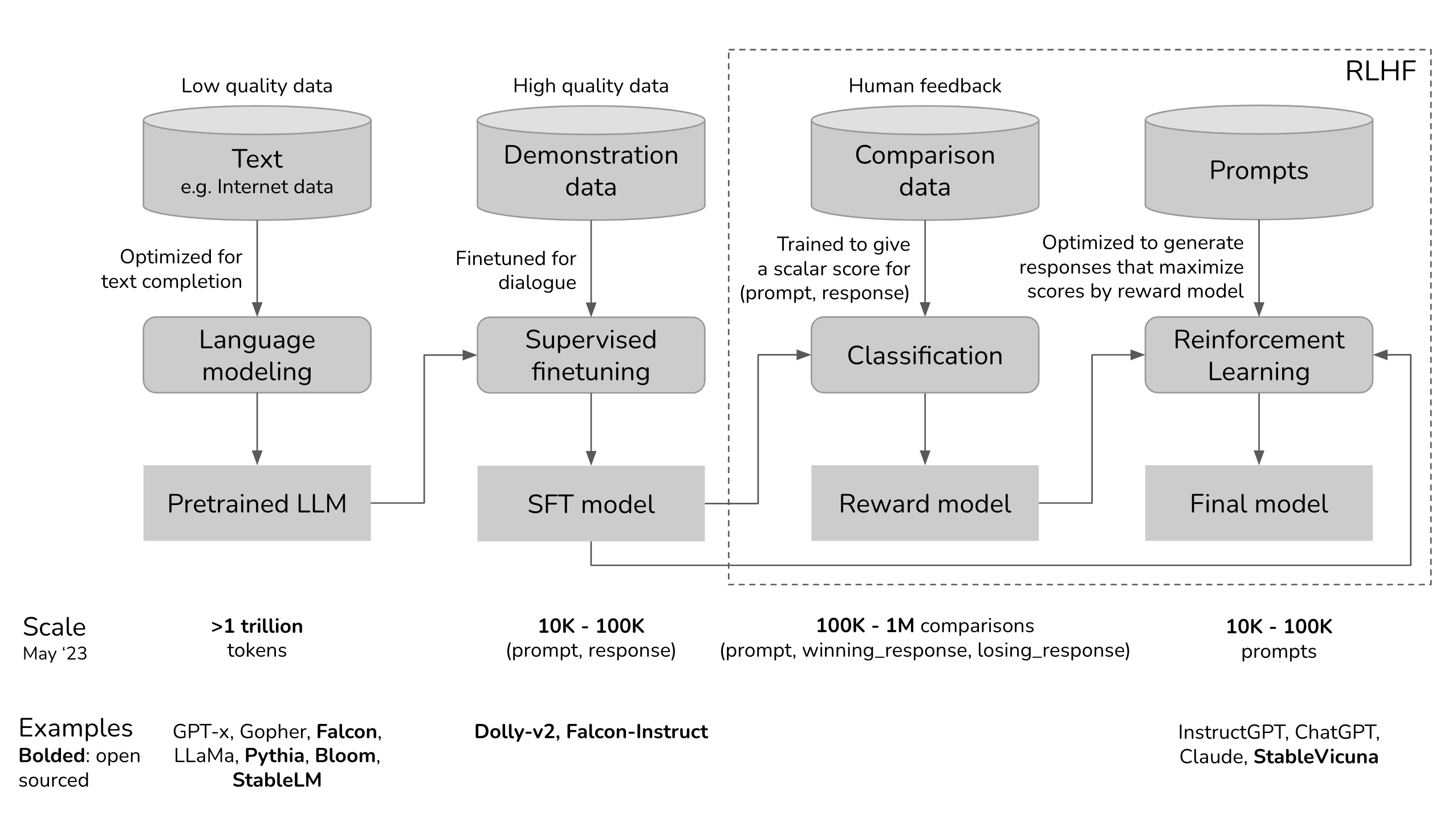
#012 Finetuning & Reinforcement Learning from Human Feedback (RLHF)
Über das folgende Tool lassen sich LLMs mit Finetuning & Reinforcement Learning from Human Feedback (RLHF) verbessern.


Über das folgende Tool lassen sich LLMs mit Finetuning & Reinforcement Learning from Human Feedback (RLHF) verbessern.
Argilla ist eine Open-Source-Plattform für die Datenkuratierung von LLMs. Mit diesem Tool kann jeder robuste Sprachmodelle unter Verwendung von menschlichem und maschinellem Feedback erstellen.
Argilla Feedback ist vollständig Open-Source und mit seinem einzigartigen Fokus auf skalierbarer menschlicher Feedback-Sammlung darauf ausgelegt, die Leistung und Sicherheit von Large Language Models (LLMs) zu verbessern.
Das Tool ist ein sehr guter Einstiegspunkt für jeden, der sich mit RLHF: Reinforcement Learning from Human Feedback befassen möchte. Im folgende Artikel, werden die Supervised fine-tuning und Reward modelling ausführlich erläutert: https://argilla.io/blog/argilla-for-llms
Weiterführende Links