#032 Kontextlänge vs Kontextsuche
Was ist sinnvoller: Eine große Kontextlänge von 100.000 Tokens bei Claude2 oder eine detaillierte Suche in einer Vektordatenbank durchzuführen und die Ergebnisse mittels Embeddings in die Promptabfrage zu integrieren?


Was ist sinnvoller? Eine große Kontextlänge wie z.B. 100.000 Tokens bei Claude2 oder eine detaillierte Suche mittels einer Vektordatenbank durchzuführen und die gefundenen Ergebnisse aus der Vektordatenbank mittels Embeddings in die Promptabfrage zu integrieren?
In dem folgenden spannenden Blogbeitrag von Pinecone wird untersucht, ob es sinnvoller ist, einen langen Kontext zu verwenden oder die Ergebnisse einer Suche in der Vektordatenbank zu nutzen, um bessere Ergebnisse zu erzielen. Pinecone ist zwar Hersteller/Betreiber einer Vektordatenbank, dennoch sind die Ergebnisse unserer Meinung nach relevant und nicht nur reines Marketing, da sie durch Studien belegt wurden.
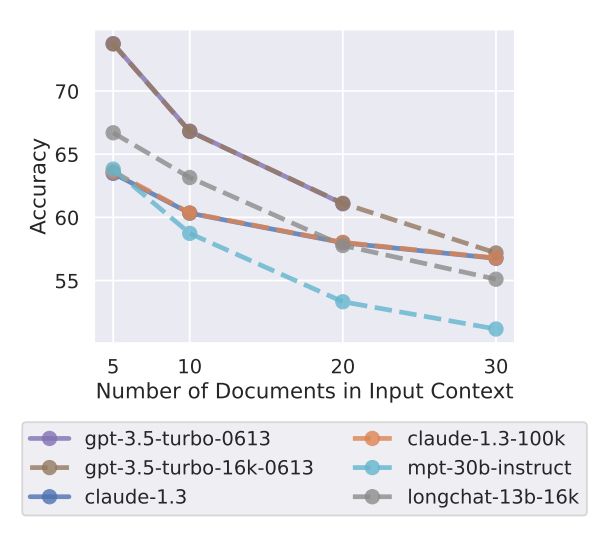
Das Einfügen des gesamten Kontextes in das Prompt bezeichnen die Autoren als "Context-Stuffing", das zu folgenden Ergebnissen führen kann:
- Die Qualität der Antworten nimmt ab.
- Das Risiko von Halluzinationen steigt.
- Die Kosten steigen linear mit größeren Kontexten.
Als Ergebnis sieht der Artikel: LLMs liefern bessere Ergebnisse, wenn ihnen weniger, aber relevantere Dokumente im Kontext gegeben werden, anstatt großer Mengen ungefilterter Dokumente.