
#013 Text Embeddings verstehen
Wort- und Satzembeddings sind die Grundlage aller LLMs (Large Language Model). Um das gewählte LLM richtig zu verstehen, ist es hilfreich, zu verstehen, wie dieses Modell trainiert wurde und welche Art des Embeddings zugrundegelegt wurde.


ChatGPT, Bard und andere Modelle finden immer größere Anwendung. Zu verstehen, wie die genutzten Modelle „denken“ und trainiert wurden, hilft bei der Einordnung und Verwendung ihrer Antworten enorm. Wort- und Satzembeddings sind die Grundlage aller LLMs (Large Language Model). Um das gewählte LLM richtig zu verstehen, ist es hilfreich, zu verstehen, wie dieses Modell trainiert wurde und welche Art des Embeddings zugrundegelegt wurde.
Um menschliche Sprache in ihrer Komplexität und ihrem Kontext in computer-verständliche Sprache zu übersetzen, ist ein Transfer von Wörtern und Sätzen in Zahlen notwendig. Dieser Prozess, in dem Wörter eine Art Bewertung zugewiesen bekommen, wird als Embedding beschrieben. Die Bewertungen der Wörter erhalten einen inhaltlichen Bezug, so dass beispielsweise das Wort „Fahrrad“ eine ähnlichere Bewertung wie das Wort „Auto“ erhält, als die des Begriffes „Hund“. Embeddings spiegeln daher also Wortähnlichkeiten bezüglich ihrer Bedeutung wider und ergänzen diese um weitere Eigenschaften der Sprache, etwa Zusammenhänge und inhaltliche Abhängigkeiten.
Übertragen auf logisch-mathematische Abbildungen sind diese Zusammenhänge in mehreren Dimensionen darstellbar. Die Dimensionen „Mensch-Gegenstand“ wird kombiniert mit „Größe“ und wäre als Matrix darstellbar, in der Begriffe eingeordnet werden können – je ähnlicher der Inhalt, desto geringer die Distanz – ähnlich einem Supermarkt, in dem Äpfel und Bananen näher aneinander platziert werden als Waschpulver oder Hundefutter.
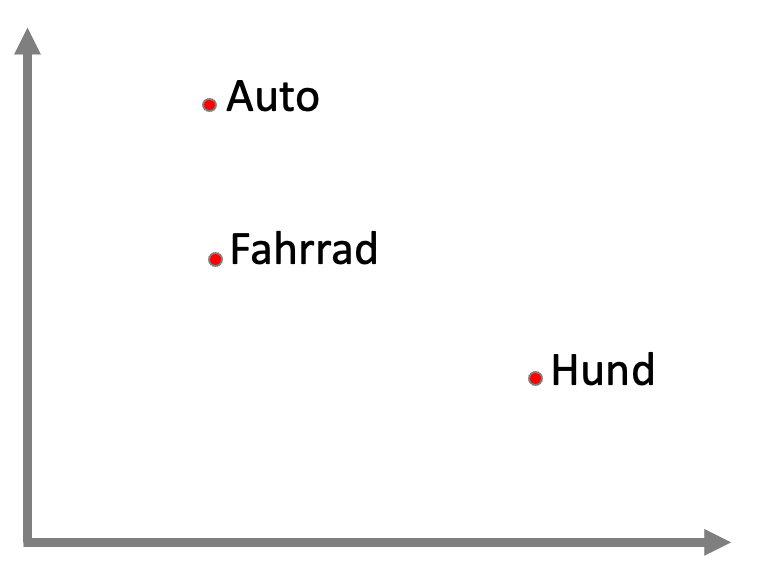
Vorstellbar ist nun, nicht nur zwei Eigenschaften – und damit Dimensionen – abzubilden, sondern mehr. Je mehr Dimensionen, umso detaillierter die Beschreibung der Eigenschaften der Begriffe und umso inhaltsvoller und genauer das Embedding – und damit die Antwortmöglichkeit des Modells. Die Dimensionen werden als Vektoren beschrieben, eine der OpenAI-Embeddings repräsentiert 1536 Dimensionen /Vektoren (zugegebenermaßen etwas schwer graphisch darstellbar). Es entsteht somit nicht ein zweidimensionales Koordinatensystem, sondern ein multidimensionales – je nach Modell mit einer bestimmten Anzahl an Dimensionen.
Diese Vektoren bringen zusätzlich den Vorteil, dass eine rein wort-basierte Suche nur genau dann „Treffer“ meldet, wenn das Wort identisch ist. In der Logik der LLMs erhält man jedoch ebenso passende „Treffer“ oder Antworten, wenn die Wortwahl ähnlich, aber nicht identisch ist, da Wörter mit ähnlichen Vektoren „aus der Nähe“ des Suchbegriffes ebenso einbezogen werden können. Es ist also nicht mehr notwendig, sich auf gleiche Benennung von Dingen oder Definitionen und Standards festzulegen, weil die Modelle durch die Nutzung und den Vergleich von Vektoren eine logische Nähe finden, übertragen und anwenden können.
Je nachdem, für welchen Zweck man AI Modelle nutzen möchte, ist es sinnvoll, zu schauen, wie und auf was diese trainiert wurden, um inhaltlich möglichst guten Output zu erhalten. Künstliche Intelligenz als Unterstützung zum Erstellen von Softwarecode benötigt anderen Input der Modelle als etwa eine medizinische Anwendung oder Bilderstellung.
Gehen wir einen Schritt weiter, stellen wir fest, dass die menschliche Sprache aber noch komplexer ist als lediglich die Einordnung von Wörtern und deren Bedeutung. Ganze Sätze als Embedding zu repäsentieren, ist ungleich umfassender, da Wortreihenfolge und Semantik eine Rolle spielen und sich in den Embeddings widerspiegeln müssen. Der Satz „Keine, ich habe Eile“ (auf die Frage: „hast Du nachher Zeit?“), hätte nach oben beschriebener Logik die gleichen Begriffe und damit gleichen Vektoren wie „ich habe keine Eile.“ – bedeutet jedoch genau das Gegenteil. Die Schlussfolgerung ist, dass zusätzlich Satz-Embeddings benötigt werden, die die Bedeutung widerspiegeln und die Wort-Embeddings ergänzen. Sätze mit ähnlichen Bedeutungen erhalten ähnliche Vektor-Größen als Satz-Embedding. Jeder Satz-Vektor mit seinen Koordinaten enthält Eigenschaften des Satzes. Komplexe Algorithmen helfen hier und ordnen dem Satz einen Vektor aus 1536 (bei OpenAI) Zahlen zu. Diese Sätze können nun ebenso in eine Matrix eingeordnet werden und erhalten je nach Vektoren unterschiedliche Distanzen zueinander. Moderne Modelle arbeiten daher alle mit Satz-Embeddings.

Nachdem die Embeddings generiert wurden, können ähnliche Embeddings mithilfe der "Cosine Similarity" leicht gefunden werden. Dadurch wird es möglich, die Embeddings später für die Kontextzusammenstellung in Prompts zu verwenden. Ein weiterer Vorteil der "Cosine Similarity" besteht darin, dass sie eine effektive Methode zur Reduktion der Dimensionalität von Daten darstellt. Diese Methode wird häufig in der Datenanalyse eingesetzt, um die Anzahl der Merkmale zu reduzieren und die Effizienz von Algorithmen zu verbessern. Darüber hinaus ermöglicht die "Cosine Similarity" die Ermittlung von Ähnlichkeiten zwischen Texten, indem sie den Kosinus des Winkels zwischen den Vektoren berechnet, die die Texte repräsentieren. Auf diese Weise kann die "Cosine Similarity" dazu beitragen, die Genauigkeit von Textanalysen und Klassifikationen zu verbessern.
Denkbar ist zusätzlich, dass dieses Modell nicht nur auf einer Sprache trainiert wurde, sondern dass gleiche Sätze in unterschiedlicher Sprache sehr dicht zugeordnet werden können.

Weiterführende Links und Text
https://twitter.com/svpino/status/1628741506826899458
https://docs.cohere.com/docs/text-embeddings
https://weaviate.io/blog/history-of-weaviate#example-of-an-embedding