
#047 Komplexe, betriebliche Probleme mit LangChain lösen
LangChain ist ein Open-Source-Framework, das Entwicklern ermöglicht, mit KI zu arbeiten und große Sprachmodelle mit externen Datenquellen zu kombinieren und komplexe Probleme im operationellen Kontext zu lösen.


LangChain ist der De-facto-Standard für das Prompt-Engineering und die Ausführung von Prompts im betrieblichen Kontext.
Manchmal reicht ein Prompt nicht aus, um eine Lösung für ein Problem zu liefern. Was kann man tun, wenn man Daten aus Dokumenten, dem Internet und einer B2B-Anwendung abfragen und auswerten muss, um ein Problem zu lösen? Eine Lösung dafür ist LangChain.
In diesem Artikel geben wir einen ersten Einblick in LangChain und erklären die grundlegenden Komponenten. Der Artikel richtet sich nicht an Techniker, sondern soll eine Übersicht geben, die jedem beim Verständnis des Frameworks helfen soll.
Aufgrund der feststehenden englischen Begriffe ist eine deutsche Übersetzung dieser Begriffe nicht sinnvoll.
Alle Details zu LangChain können in der öffentlichen Dokumentation nachgelesen werden:
https://python.langchain.com/docs/get_started/introduction.html
Was ist das, warum sollte man es nutzen und wie funktioniert es?
LangChain ist ein Open-Source-Framework, das Entwicklern ermöglicht, mit KI zu arbeiten und große Sprachmodelle wie GPT4 mit externen Rechen- und Datenquellen zu kombinieren. Das Framework wird derzeit als Python- oder JavaScript-Paket (speziell TypeScript) angeboten.
Um zu verstehen, welches Problem LangChain löst, muss man sich zunächst bewusst sein, dass ChatGPT und andere Chat-Schnittstellen immer durch die Kontext-Länge eingeschränkt sind, keine "Erinnerungen" haben und in der Regel keine Aktionen ausführen können. So können in den meisten großen Sprachmodellen keine langen Texte eingefügt werden. Zwischenergebnisse können nicht gemerkt werden und der Aufruf von Dritt-Tools zur Weiterverarbeitung ist in der Regel nicht möglich.
Komponenten
Im wesentlichen besteht aus den folgenden Komponenten:
- Model I/O: Schnittstelle zu Sprachmodellen
- Retrieval: Schnittstelle zu anwendungsspezifischen Datenquellen
- Chains: Erstellen von Chains zum Aufruf
- Memory: Persistieren von Anwendungsstatus zwischen dem Ausführen einer Chain
- Agents: Flexible Aufrufe von Chains zur Ausführung von Aufgaben mittels Tools
- Callbacks: Protokollieren und streamen von sequenziellen Chains
Im folgenden erklären wir die einzelnen Komponenten
Model I/O
Unter Model I/O versteht LangChain die Prompts, Prompt-Templates, Sprachmodelle (LLMs) und Outputparser.
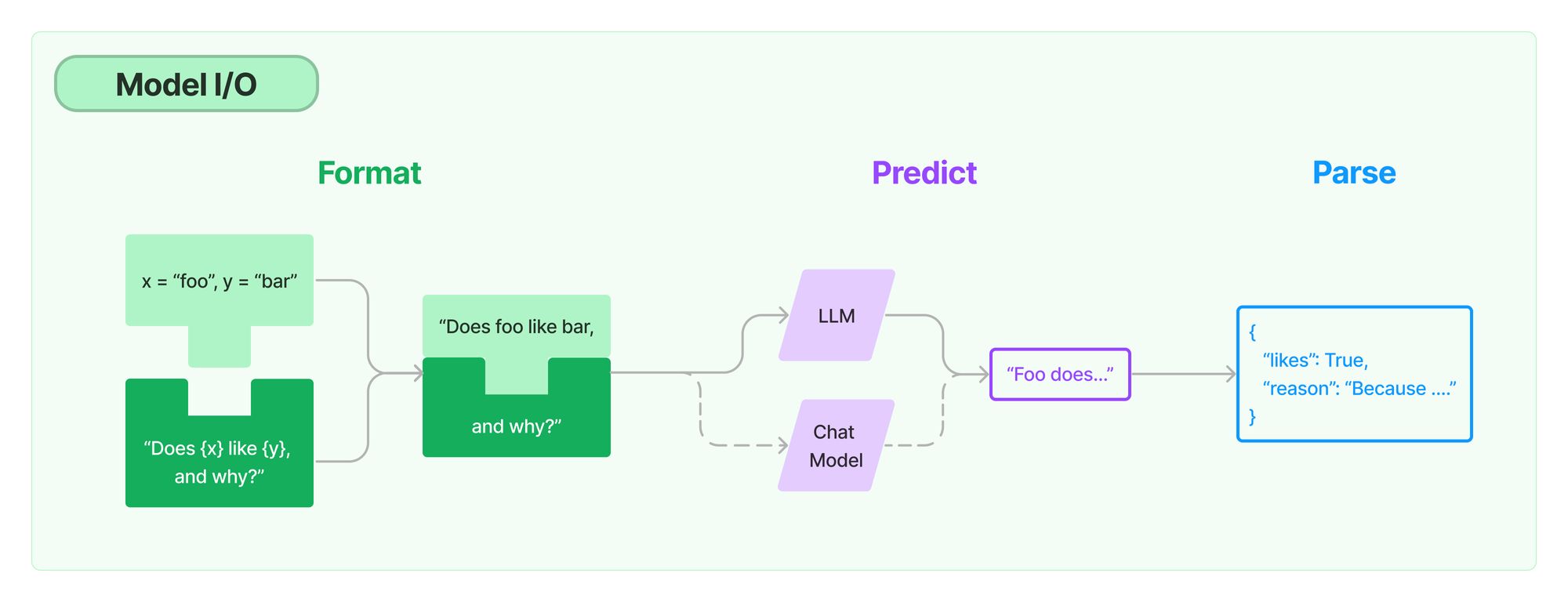
Prompt-Templates sind vorgefertigte Vorlagen zur Generierung von Prompts für LLMs. In der Regel werden Platzhalter durch den jeweiligen konkreten Input ersetzt. Für die Prompt-Templates gelten dieselben Bedingungen und Vorgaben wie für Prompts. Neben Beispielen und Kontext können auch Chain of Thought oder andere Anweisungen enthalten sein.
Die Sprachmodelle (LLMs) sind entweder die Completion- oder Chat-Modelle, die entweder nur ein Prompt vervollständigen oder Chat-Messages à la ChatGPT aufnehmen.
Outputparser verarbeiten die Ergebnisse der Sprachmodelle und sind beispielsweise in der Lage, Listen, Datumsangaben, Datenstrukturen usw. zu erzeugen.
Retrieval
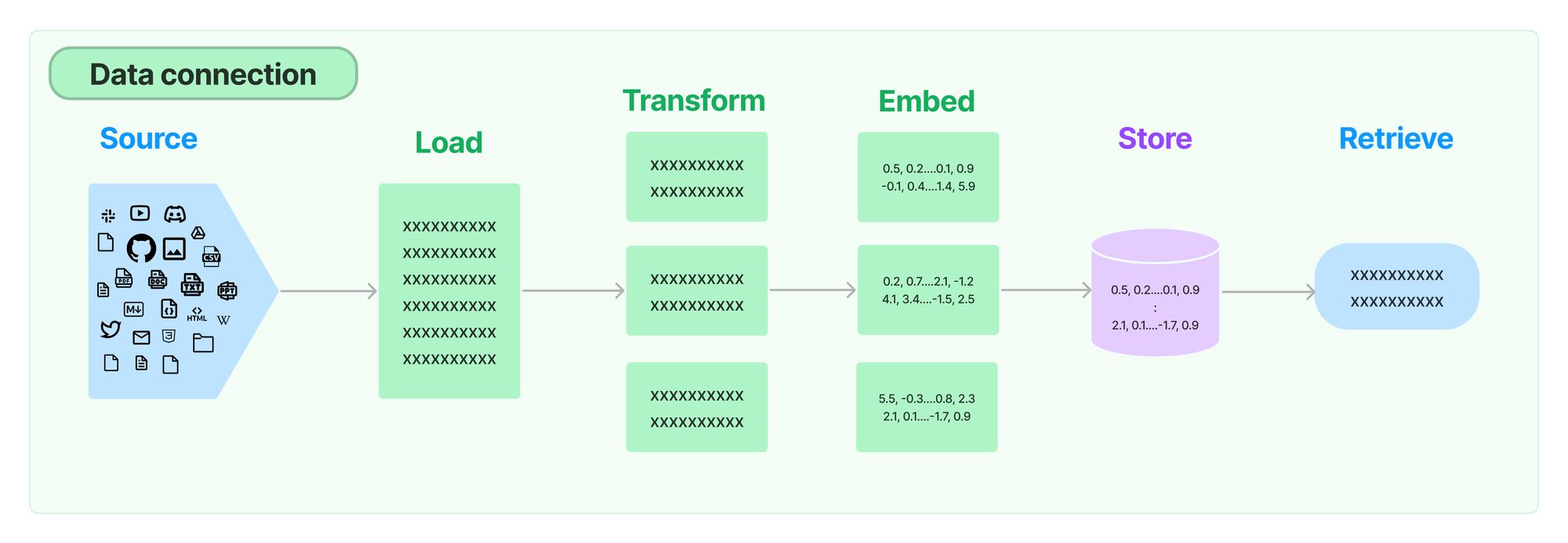
Da die Kontext-Länge bei LLMs in der Regel beschränkt sind, sind Mechanismen zum Umgang mit großen Datenmengen notwendig. Da die LLMs in der Regel mit öffentlichen Daten trainiert worden sind, ist z.B. die Verwendung internen Informationen wie z.B. eine Intranet-Seite oder ein zu langer interner Text im Kontext nicht ohne weiteres möglich.
Um dieses Problem zu lösen, werden in einem Prozessschritt vorab dies Texte vektorisiert und in eine entsprechende Vektordatebank als sogenannte “Embeddings” gelegt. (Siehe auch https://efec.de/text-embeddings-verstehen/ und https://efec.de/kontextlange-vs-kontextsuche/).
In einem zweiten Schritt wird dann später die Query (das Prompt) ebenfalls vektorisiert. Über eine Ähnlichkeitssuche werden die ähnlichsten Embeddings aus der Datenbank erneut ausgelesen und als Kontext der Anfrage hinzugefügt.
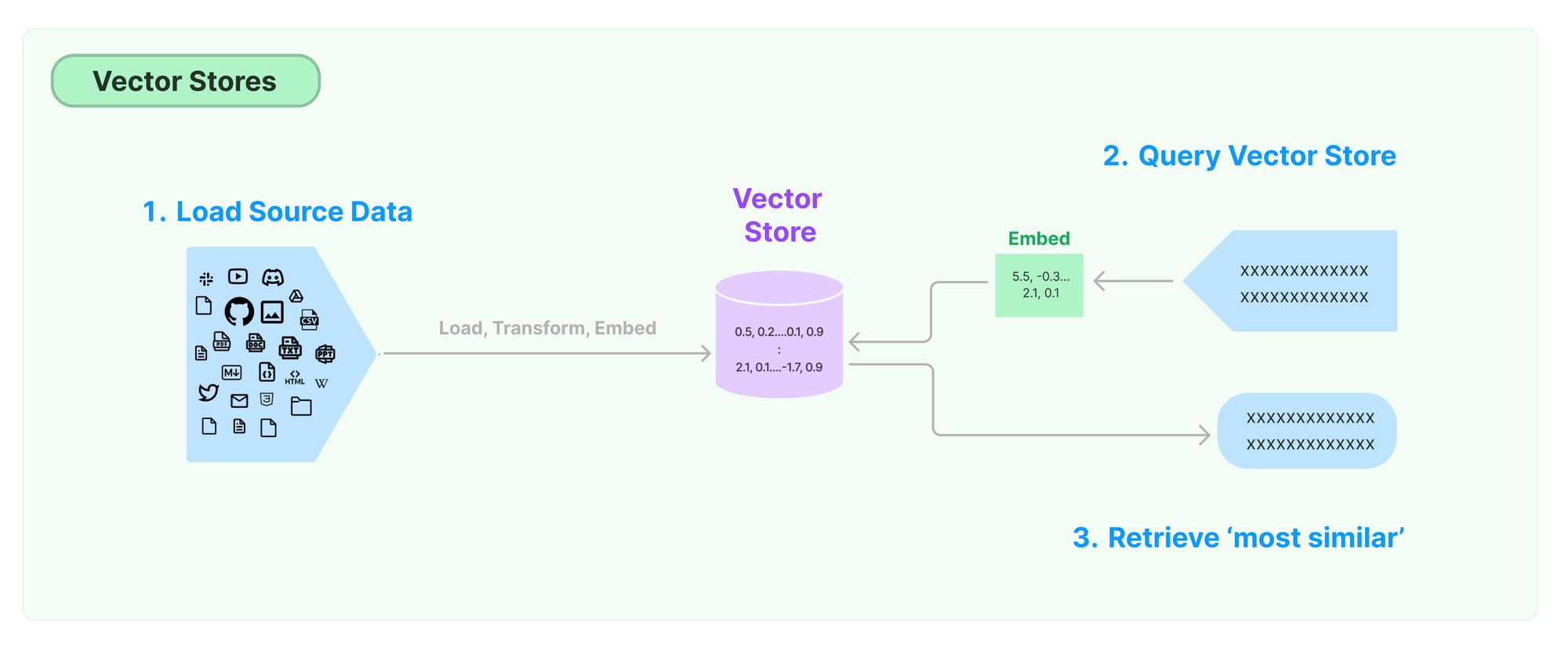
Auf diese Weise können interne Informationen dem Kontext hinzugefügt werden, wobei die Länge des Kontexts berücksichtigt wird.
LangChain bietet verschiedene sogenannte "Document Loaders" zur Erstellung von Embeddings an. Besonders erwähnenswert sind dabei CSV-Dateien und -Ordner, HTML, JSON, Markdown und PDF. Mithilfe dieser Loader können Dokumente in Chunks aufgeteilt und als Embeddings erstellt werden.
Chains
Zur Ausführung von Anfragen an eine KI, die über eine Prompt hinausgehen, bietet LangChain die sogenannten Chains. Chains sind dabei die Verknüpfung von Model I/O, Retrieval, Memory, Agents und Callbacks und bilden den eigentlichen Kern von LangChain. Chains können dabei kombiniert werden.
LangChain unterstützt verschiedene Arten von Chains, um verschiedene Aufgaben auszuführen und verschiedene Arten von Anwendungen zu erstellen. Die wichtigsten Chains sind:
- LLM Chains: Der Aufruf eines LLMs
- Router Chains: Dynamische Auswahl der nächsten Chain anhand der Ergebnisse einer Chain
- Sequentielle Chains: Aufruf von zwei oder mehr Ketten für unterschiedliche Aufgaben
- Transformation Chains: z.B. zum Zusammenfassen von Dokumenten
- Document Processing Chains: Zur Entwicklung von Fragen und Antworten auf benutzerdefinierten Daten / Dokument
In Chains sind die Aktionen, die ausgeführt werden, fest einprogrammiert. Dynamische Aktionen erlauben den sogenannten Agents (siehe unten).
Memory
Unter "Memory" werden in LangChain die Mechanismen verstanden, mit denen Zwischenergebnisse geschrieben und gelesen werden können.
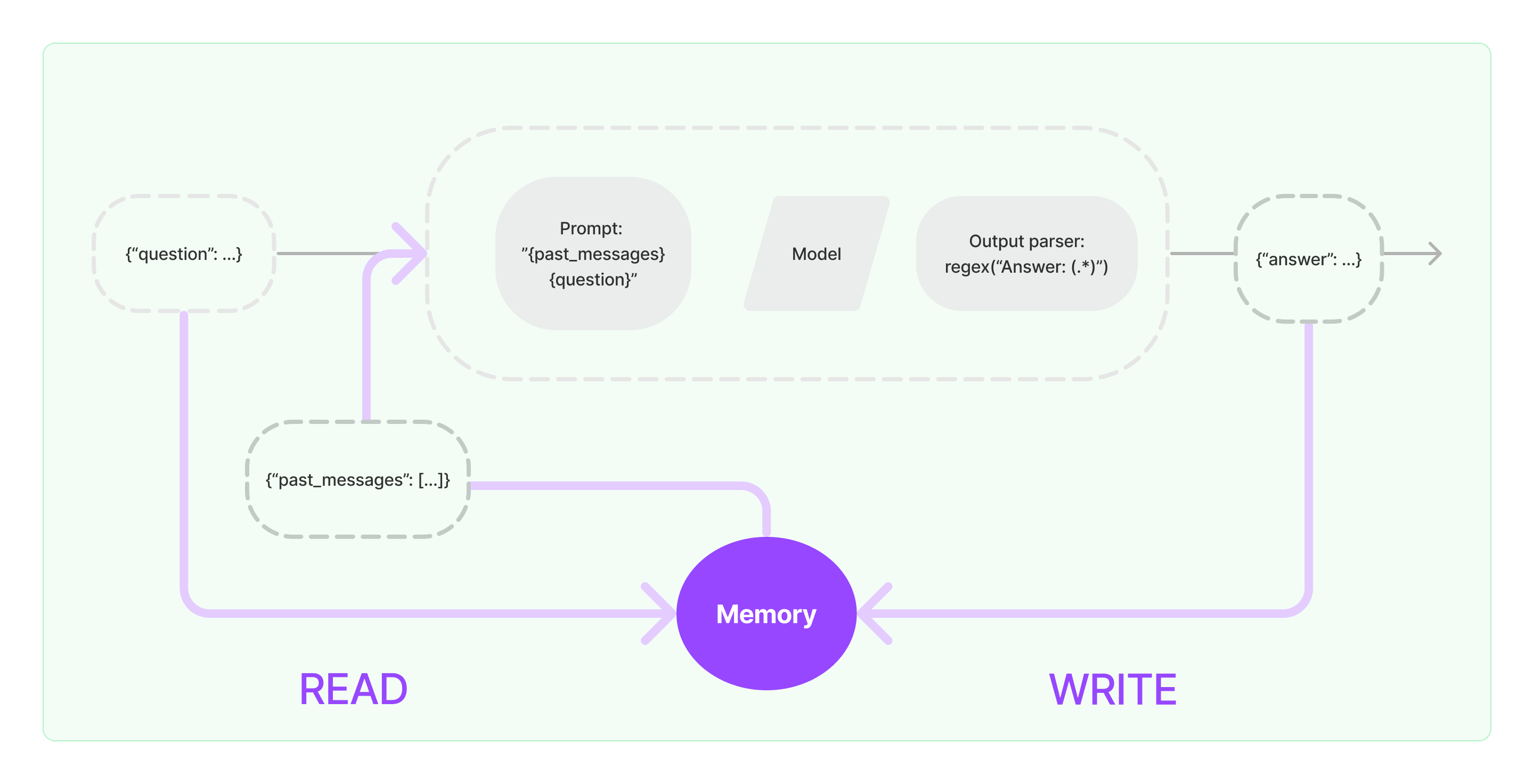
Für die Speicherung stehen je nach Anwendungsfall verschiedene "Buffer" zur Verfügung, wie z.B. ConversationBufferMemory, ConversationSummaryMemory oder VectorStoreBackendMemory. Die Verwendung hängt stark vom jeweiligen Anwendungsfall ab.
Agents
Die Idee der Agents ist, dass man im Gegensatz zur Chain, in der die Aktionen fest verdrahtet sind, eine LLM entscheiden soll, welche nächsten Aktionen in welcher Reihenfolge für die Bewältigung einer Aufgabe notwendig sind.
LangChain stellt die folgenden Agent-Typen bereit:
- Conversational
- OpenAI functions
- OpenAI Multi Functions Agent
- Plan and execute
- ReAct
- ReAct document store
- Self ask with search
- Structured tool chat
- XML Agent
Besonders hervorzuheben ist dabei das ReAct-Konzept. Die Auswahl, welche Aktion die nächste relevante ist, wird unter anderem durch das sogenannte ReAct-Konzept bestimmt (https://arxiv.org/abs/2210.03629).
Tools werden die Funktionen genannt, die ein Agent aufruft. Hier können auch eigene Tools, sogenannte Custom Tools, erstellt werden, die je nach Aufgabe ein individuelles Problem lösen. Anhand der textlichen Beschreibung, wofür dieses Tool geeignet ist, entscheidet dann der Agent, ob dieses Tool relevant ist. Am Beispiel der Anfrage an ein internes CRM-System könnte die textliche Beschreibung z.B. folgendermaßen lauten:
“Useful for when you need to answer questions about a customer’s history”
Callbacks
Zur Vollständigkeit sollten hier auch noch die Callbacks erwähnt werden, die für Logging, Monitoring und Streaming sinnvoll eingesetzt werden können.
Zusammenfassung
Neben den in "#020 B2B Einsatzszenarien für generative KI" (https://efec.de/b2b-einsatzszenarien-fur-generative-ki/) beschriebenen Einsatzszenarien für KI kann LangChain unter anderem auch für Chatbots, Fragen-Antworten über Daten, Textzusammenfassung, Entwicklertools und die Kombination aus all diesen Bereichen angewendet werden. Es ist eine Art Lego-Bausatz, um komplexe Probleme mit KI zu lösen.
LangChain ist ein Open-Source-Framework, das Entwicklern ermöglicht, mit KI zu arbeiten und große Sprachmodelle mit externen Datenquellen zu kombinieren. Es bietet verschiedene Komponenten wie Model I/O, Retrieval, Chains, Memory, Agents und Callbacks, um komplexe Probleme im operationellen Kontext zu lösen.
Abbildungen wurden von https://python.langchain.com/docs/get_started/introduction.html übernommen.